Google Anuncia o Robots.txt Report no Google Search Console: veja como acessar e analisar os dados
 Felipe Bazon
Felipe Bazon
O Robots.txt Report é a nova funcionalidade no Google Search Console que entrou e colocou fim ao Robots.txt Tester. Com ela, é possível identificar se há erros no crawling do Robots.txt, a data do último rastreamento e mais.
Em 15 de novembro de 2023, o Google anunciou a adição do Robots.txt Report ao Google Search Console.
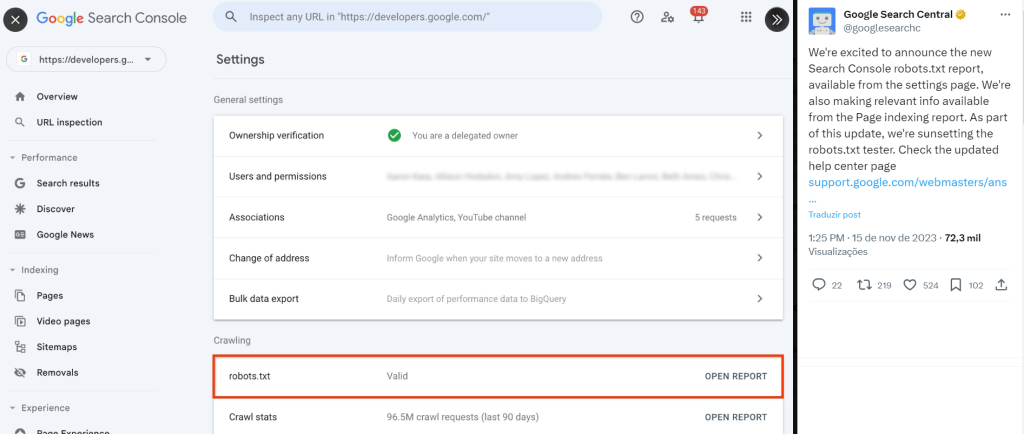
Com ela, é possível identificar se o arquivo robots.txt é considerado válido e, também, abrir um report da URL crawleada, que indica também a data do último rastreamento, o status, o tamanho em bytes e também eventuais problemas com o arquivo.
A nova funcionalidade permite entender melhor o comportamento dos crawlers junto a tal arquivo no seu site. Analisamos a documentação do Google e testamos a funcionalidade para entender como é e explicar como um profissional, um consultor ou uma agência de SEO podem utilizá-lo. Continue conosco e confira!
O que é o Robots.txt?
Está começando em SEO e chegou até aqui porque viu notícias dos updates, mas não sabe o que é exatamente o Robots.txt? É o primeiro arquivo que o googlebot solicita em um site. Ele define se determinados bots podem ou não rastrear um website ou determinadas URLs dele.
Não existe um prejuízo real na inexistência do arquivo Robots.txt, mas se ele for configurado incorretamente, ou se tiver falta de acesso, pode causar prejuízos à performance orgânica do site. Por isso, entender como o Googlebot vê o Robots.txt e ter acesso a um report direto no GSC pode ajudar muitos profissionais da área.
O que muda com o Robots.txt Report?
Para acessá-lo, basta abrir o Google Search Console, ir na parte de Settings. Lá, desca até a parte de Crawling, onde terá o report de Robots.txt. É só clicar que você será levado a uma página mais detalhada do report.

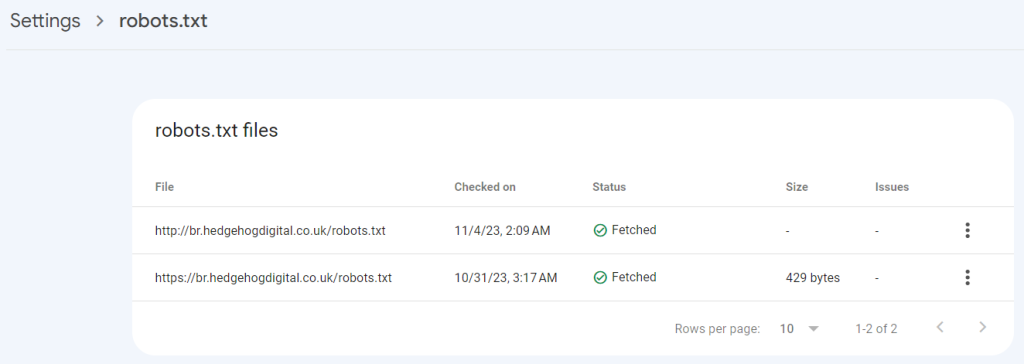
Veja todas as informações disponibilizadas pelo report, conforme comunicação do próprio Google:
- Caminho do arquivo ou File Path: é a URL do Robots.txt. Geralmente, será seusite.com.br/robots.txt. Note que ele analisará tanto a http:// quanto https:// caso disponível.
- Status da busca: o GSC reporta se foi possível ao crawler conseguir obter o Robots.txt do seu site. Aqui, existem diferentes resultados possíveis, como o ‘não encontrado/not fetched’ por erro 404, no caso de arquivo inexistente, ou por outros erros de indexação. Por fim, caso seja encontrado, a resposta será apenas “fetched”.
- Data do último rastreamento do arquivo;
- Tamanho do arquivo;
- Quantidade de problemas no Robots.txt
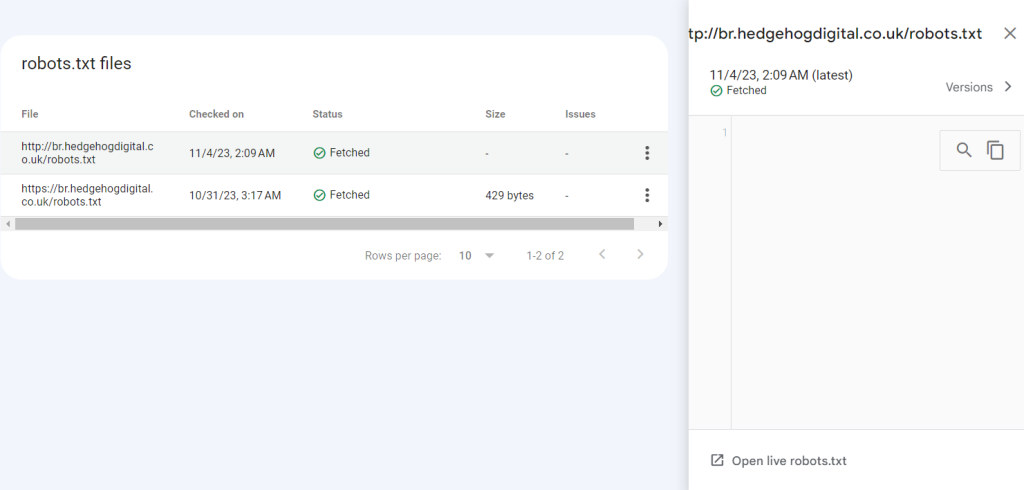
Ao clicar na URL rastreada, o GSC abre um painel lateral que permite ver as versões do arquivo e também um teste live para entender o que, exatamente, o bot conseguiu rastrear. No caso das versões antigas, é importante ressaltar que ele só guarda os últimos 30 dias.
O que fazer se o seu Robots.txt não for acessado pelo Google?
Quando se trata da visibilidade do seu site nos mecanismos de busca, o arquivo robots.txt desempenha um papel crucial. No entanto, há situações em que o Google pode enfrentar dificuldades ao buscar o arquivo. Vamos explorar o que fazer em cada caso.
Ausência do Arquivo robots.txt
Se o arquivo robots.txt não é encontrado para um domínio ou subdomínio, não há realmente um problema. Ele simplesmente assume que pode rastrear todas as páginas no seu site.
Problemas de Acesso ao robots.txt
Se o Google encontra o arquivo, mas não consegue acessá-lo, a seguinte sequência de eventos ocorre, conforme documentação do próprio buscador, que traduzimos por aqui:
- Nas primeiras 12 horas, o Google interrompe o rastreamento do site, mas continua tentando buscar o arquivo robots.txt.
- Se não for possível obter uma nova versão, o Google utilizará a última versão válida pelos próximos 30 dias, persistindo na tentativa de buscar uma versão atualizada.
No caso de erros que persistam por mais de 30 dias, o Google passará a agir como se o Robots.txt não existisse. Agora, se os problemas forem de disponibilidade do site, o Google interromperá seu rastreamento. Nesse caso, é fundamental atuar com uma frente de SEO técnico para garantir a otimização correta do website.
Problemas no Conteúdo do Arquivo robots.txt
Quando o Google encontra e busca o arquivo robots.txt, ele analisa cada linha do conteúdo e ignora aquelas com erros ou que não puderem ser interpretadas pelo crawler. Arquivos vazios são interpretados como irrestritos, dando acesso completo às URLs do site.
Você se preocupa com o Robots.txt de um site quando começa a auditá-lo ou trabalhar em otimizações técnicas? Se sim, é hora de já testar a nova funcionalidade. Quer ficar por dentro de outras novidades do mundo do SEO? Confira nossa lista de 14 Newsletters de SEO para se manter informado. Ah, e, é claro, assine a nossa!
Sobre o autor

Felipe Bazon
Felipe Bazon é CSO da Hedgehog Digital e um dos profissionais de SEO mais renomados do país com reconhecimento internacional. Em 2015 e 2020 foi eleito profissional do ano de SEO no Brasil. Além da vasta experiência operacional, é também orador regular em eventos como E-show, OME Expo, Des-Madrid, Digitalks, RD Summit e Brighton SEO.
Comentários:


