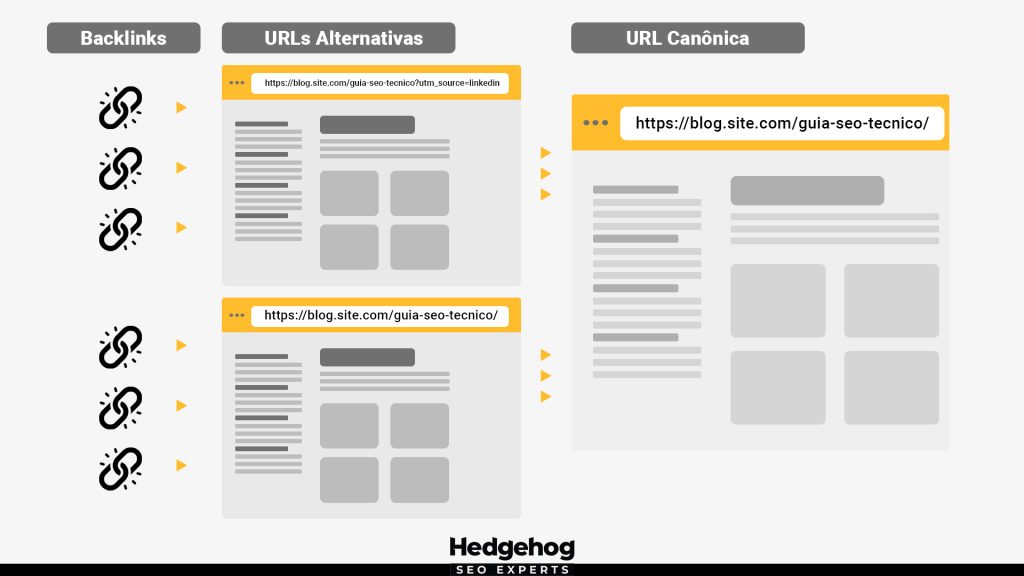
A tag canonical tem como função indicar ao Google qual versão deve ser tratada como principal entre páginas duplicadas. Com isso, evita a dispersão de sinais, previne a canibalização de palavras-chave e melhora a eficiência de rastreamento, concentrando backlinks e autoridade em uma única URL e fortalecendo os sinais enviados ao buscador.
Imagine esse cenário: publicamos um artigo impecável, ajustamos cada heading e, claro, adicionamos a tag canonical como manda o manual.
Dias depois, digitamos a palavra-chave no Google e… nada. O buscador decide ranquear outra URL – ou, pior, nos deixa fora do índice como se o conteúdo nunca tivesse existido.
Se isso soa familiar, bem-vindo ao multiverso de URLs, um cenário onde versões paralelas da mesma página disputam a mesma energia de ranqueamento.
É como se cada variante abrisse um portal próprio, desperdiçando eficácia de rastreamento, diluindo engajamento e confundindo o algoritmo sobre qual delas merece o topo da busca.
O resultado? Nenhuma versão ganha força suficiente para chegar ao palco principal da SERP (página de resultados do mecanismo de busca).
Neste guia, vamos explicar o que é a tag canonical, fechar esses portais, reunir todos os sinais em uma única realidade canonical e mostrar ao Google qual URL deve liderar a missão – sem loop infinito, redirecionamentos fantasma ou canônicos cruzados.
O que é a tag canonical?
Tecnicamente, trata-se de um elemento <link> inserido no <head> da página que aponta para a versão principal do conteúdo. Ou seja, aquela que deve concentrar os sinais de ranqueamento.
<link rel=”canonical” href=”https://exemplo.com/url-oficial/” />
Quando o bot encontra essa indicação, ele entende que apenas a versão canônica deve ser exibida.
Em outras palavras, a canonical é a URL preferida dentre um conjunto de páginas consideradas duplicadas.
Em um e-commerce, por exemplo, pode haver uma série de páginas iguais do mesmo produto pelo uso de parâmetros.
Mas essas infinitas duplicatas não devem ser exibidas nas SERPs porque
- afeta a eficácia de rastreamento do Google,
- haveria canibalização entre elas.
Nesse sentido, a tag canonical é fundamental para indicar qual versão deve ser indexada, evitando, assim, essas questões.

Canonical não é redirecionamento
É muito importante entender esse ponto:
- 301/308: teletransporta o usuário e o bot para outra URL (é um sinal forte, mas pode prejudicar o UX se for usado demais).
- Tag canonical: sinaliza qual URL deve ranquear, mas o usuário continua onde está (é um sinal um pouco mais fraco, ideal para variações legítimas de conteúdo).
Por que tag canonical é importante no SEO?
Imagine o Google como um bibliotecário que precisa organizar trilhões de páginas em intervalos muito curtos. Nosso trabalho como SEO é facilitar a vida do Google, no sentido de fazer com que ele nos ache mais facilmente.
Sendo assim, a ideia é adotarmos boas práticas que não farão com que o Google “perca tempo” no nosso site com o que é irrelevante, certo?
E é aqui que a canonical tag entra: ela nos auxilia nos seguintes pontos:
- Previne conteúdo duplicado: parâmetros de campanha, filtros de cor/tamanho, versões HTTP vs. HTTPS.
- Consolida autoridade: todos os backlinks apontam para a mesma URL.
- Melhora a eficácia de rastreamento: o Googlebot navega menos em becos sem saída.
- Evita canibalização: só uma página concorre pelos principais termos da marca.
Em uma loja virtual, por exemplo:
- URL real: https://exemplo.com/produto/camisa-verde
- Canonical errada: https://exemplo.com/produto/camisa-azul
Resultado? O Google pode considerar a página da camisa verde como duplicata da página da camisa azul e… adeus posições.
Confira um exemplo correto:
- URL acessada: https://exemplo.com/produto/?utm_source=instagram
- Canonical correta: https://exemplo.com/produto/
Assim você garante que os parâmetros de tracking não criem duplicatas indesejadas.

Continue lendo: Atualização das Diretrizes de Canonização do Google: entenda as mudanças
Como o Google escolhe sua versão canonical?
Você pode definir explicitamente que https://exemplo.com/produto-oficial é a URL canonical. Ainda assim, o Google verifica uma série de sinais para confirmar essa indicação. Em geral, a prioridade desses sinais segue esta ordem:
| Nível de confiança | Sinal avaliado | Como o Google interpreta |
| 1 | Redirecionamento 301 | A URL de destino vira a referência única e todos os sinais (autoridade, relevância, histórico) são consolidados nela. |
| 2 | Tag rel=”canonical” em HTML | Sinal muito forte, desde que não conflite com um 301, expressa a preferência editorial do site. |
| 3 | Header HTTP rel=”canonical” | Mesma força da tag HTML; ideal para PDFs e outros arquivos não-HTML. Ainda assim, “perde” para redirecionamentos. |
| 4 | Sitemap XML | O <loc> listado como canônico é um bom indício, mas não é prova final, pode ser ignorado se outros sinais discordarem. |
| 5 | hreflang | O Google tenta casar idioma/região e versão canonical, se houver incoerência, ele escolhe a URL que mantém a matriz coerente. |
| 6 | Links internos | A versão que recebe mais links internos indica ao Google a página que o site prioriza e, por isso, tem peso adicional. |
| 7 | Links externos + histórico | Se a maioria dos backlinks (e engajamento passado) aponta para uma versão antiga, o Google hesita em trocá-la por uma nova. |
Resumo prático: 301 > rel=canonical > sitemap / hreflang > linkagem.
E não se esqueça: seu sinal pesa, mas não é decisivo.
Quando o Google seleciona uma URL canonical diferente da que foi declarada, pode ser devido a algumas destas situações:
- Canonical conflita com 301: se a página A declara <link rel=”canonical” href=”A”>, mas redireciona para B, o Google considera B como canonical pela coerência do redirecionamento.
- Canonical aponta para URL não indexável:
- noindex
- Bloqueada no robots.txt
- 404/410 (nenhum algoritmo irá canonizar uma página que ele mesmo não pode indexar).
- Loop ou cadeia de canonicals infinita: A > canonical B > canonical C > … volta para A. Resultado: o Google interrompe o ciclo e decide sozinho qual URL vai considerar.
- Diferenças mínimas entre as versões de páginas: se há pouca variação entre as páginas, o buscador pode consolidar tudo na que carrega mais rápido ou recebe mais links, mesmo que outra esteja marcada como canonical.
- E-commerce com parâmetros + canonical duplicada: URLs do tipo ?cor=azul declaradas como canonicals criam sinais confusos. Assim, o buscador tende a preferir a versão limpa e sem parâmetros.
- hreflang atravessado: se /en/product define canonical /pt/product, mas esta URL possui outra canonical ou estácomo noindex, o algoritmo ignora o comando e reorganiza as versões de idioma por conta própria.
Checklist de conformidade da tag canonical
- Canonical e 301 devem apontar para a mesma URL.
- Não direcione a canonical para uma página com noindex.
- Evite canonicals cruzadas entre domínios diferentes sem redirecionamento 301.
- Inclua a canonical na primeira renderização (não injete via JavaScript).
- Seja consistente em https vs. http, final / e uso de www.
Seguindo essas regras, você aumenta significativamente a chance de o Google respeitar a URL definida e evita que o algoritmo escolha outra versão.
Como verificar qual URL o Google considera canonical?
Antes de sair ajustando qualquer tag canonical, você precisa garantir que está na mesma página que o Google. Afinal, não adianta declarar uma canonical que o buscador já decidiu ignorar.
A boa notícia: descobrir qual URL o Google definiu como canonical é rápido e simples, e pode ser feito com as ferramentas de SEO que costumamos usar no dia a dia.
Usando o Google Search Console (Inspeção de URL)
Essa é a maneira mais fácil e direta. Acesse o Google Search Console e cole a URL que deseja conferir. Em seguida, clique em Inspeção de URL.
Role até a seção Page indexing e confira:
- “User-declared canonical” (a versão que você declarou);
- “Google-selected canonical” (a versão que o Google efetivamente considera).
Se ambas forem diferentes, bingo: sua tag canonical está sendo ignorada pelo buscador. Hora de revisar com atenção.

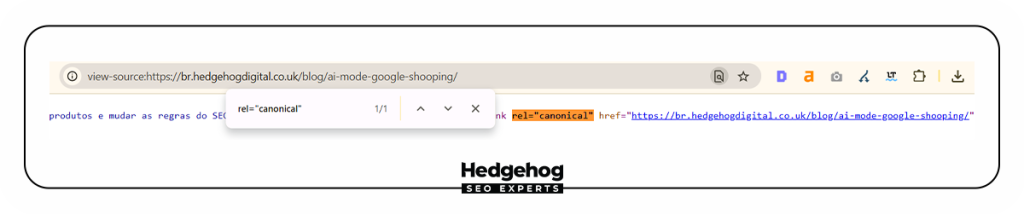
View Source direto do navegador
Outra alternativa prática é verificar diretamente o HTML entregue ao Googlebot.
- Abra a página em modo anônimo (assim você evita ver versões cacheadas ou personalizadas).
- Pressione Ctrl + U (Windows) ou Cmd + Option + U (Mac) para abrir o código-fonte.
- Com a página aberta, dê um Ctrl + F e busque por rel=”canonical”.
- Confira se a URL declarada bate exatamente com a que você deseja indexar — com protocolo (http/https), presença ou não de www, e a barra final (/) no final da URL.
Qualquer discrepância aqui pode causar problemas de indexação ou de interpretação da página pelo Google.
Linha de comando com curl -I (headers HTTP)
Em alguns casos raros, a canonical não está declarada no HTML, mas no header HTTP (muito comum com PDFs e outros arquivos não-HTML). Para isso, o terminal deve ser seu melhor amigo.
Execute no terminal o comando:
curl -I https://exemplo.com/minha-pagina
No retorno do comando, procure pela linha que começa com:
Link: <https://…>; rel=”canonical”
Confira novamente se a URL declarada está exatamente como você deseja.
Screaming Frog para auditorias mais completas
Agora, se você precisa verificar isso em escala e detectar conflitos com precisão, o Screaming Frog é a ferramenta ideal. Siga o roteiro abaixo:
- Abra o Screaming Frog e selecione o modo Spider.
- Insira o domínio que deseja analisar e clique em Start.
- Após a conclusão, navegue até a aba Canonicals para visualizar rapidamente:
- Canonical Link Element (canonicals declaradas via HTML);
- Canonical HTTP Header (canonicals declaradas no header HTTP);
- Rel Canonical Status (verifique o código de resposta HTTP dessas páginas, como 2xx ou 3xx).
- Filtre por Canonicalised para listar páginas cujo canonical aponta para outra URL (potencial problema de duplicação ou conflito).
- Exporte essa lista e priorize as correções nas páginas mais relevantes ou que trazem mais tráfego. Para fazer isso com maior precisão, cruze essas informações com a aba do Analytics integrada no próprio Screaming Frog.
Em poucos minutos, você tem um diagnóstico preciso sobre a saúde das suas canonicals. Corrija eventuais problemas o quanto antes. Tags canonicals mal configuradas podem comprometer o desempenho nos resultados de busca.

Quando e como usar a tag canonical?
Diretriz prática: Toda página deve conter uma tag canonical autorreferencial, apontando para si mesma, como sinal claro de preferência. Quando duas (ou mais) URLs exibirem exatamente o mesmo conteúdo, especifique qual é a versão principal na canonical.
Importante: o Google não recomenda mais usar tags canonical em conteúdo sindicado. Nesses casos, os sites parceiros devem impedir a indexação aplicando as meta tags adequadas, como noindex.
1. Variações de produto no e-commerce
Filtros de cor, tamanho ou voltagem podem gerar URLs diferentes, mas com o mesmo conteúdo. Ao exibir https//:www.site.com/produto/camisa/vermelha?tam=m, o Google enxerga duas páginas idênticas: uma limpa (/camisa/) e outra com parâmetros.
Como evitar: insira em cada variação (/camisa/vermelha?tam=m) a tag canonical autorreferencial na URL principal:
<link rel=”canonical” href=”https//:www.site.com/produto/camisa/”>
Mantenha os dados estruturados de produtos completo no URL “mãe” para centralizar comentários, avaliações e demais atributos — evitando que o buscador considere as variações como conteúdo duplicado.
2. Parâmetros de campanha e filtros
Parâmetros como utm_source=email ou ?sort=price-desc não alteram a essência da página, servem apenas para monitoramento ou ordenação.
Sempre que um parâmetro for adicionado, aponte a canonical para a versão “limpa” da URL. Por exemplo, em https//:www.site.com/curso-seo?utm_source=facebook use:
<link rel=”canonical” href=”https//:www.site.com/curso-seo”>
Caso o filtro mude apenas detalhes de exibição (por exemplo, exibir apenas uma categoria específica), combine noindex no cabeçalho HTTP com a tag canonical, para que o Google concentre seu rastreamento na página principal.
3. Migrações (HTTP/HTTPS ou WWW/domínio raiz)
Durante a transição para HTTPS ou para unificar WWW vs. não-WWW, podem surgir temporariamente URLs duplicadas: http://site.com e https://site.com, ou www.exemplo.com e exemplo.com.
Mantenha o redirecionamento 301 ativo e, na página destino, adicione a canonical autorreferencial. Por exemplo:
# .htaccess ou configuração do servidor
Redirect 301 /guia-seo http://site.com/guia-seo/
<!– no <head> da página destino –>
<link rel=”canonical” href=”https://site.com/guia-seo/”>
Dessa forma, o Google entende imediatamente qual é a versão oficial, otimiza o processo de rastreamento e evita confusões durante a indexação.
4. PDF x versão HTML
Quando um mesmo conteúdo existe em HTML e em PDF, é importante priorizar a versão em HTML para indexação — ela costuma oferecer melhor experiência ao usuário e desempenho nos resultados de busca.
Configuração recomendada:
No arquivo PDF (/ebook-seo.pdf), adicione no cabeçalho HTTP ou via meta tag a URL HTML canônica:
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <https://site.com/ebook-seo/>; rel=”canonical”
Na página HTML (/ebook-seo/), inclua um link “Baixar PDF” para download.
Se desejar que o PDF não seja indexado, aplique a diretiva noindex no cabeçalho HTTP do arquivo.
Assim, o Google identifica claramente que a página HTML é a versão principal, enquanto o PDF fica disponível apenas como recurso de apoio.
5. Paginações longas (?page=2, /page/3/…)
Em categorias extensas ou blogs com muitos posts, as páginas subsequentes (?page=2, /page/3/ etc.) exibem itens semelhantes à página inicial, o que pode gerar agrupamento de conteúdo duplicado.
Por isso, defina a canonical de cada página paginada apontando para a primeira página da lista. Por exemplo, em /blog/page/3/ inclua:
<link rel=”canonical” href=”/blog/”>
Mantenha também as tags rel=”prev” e rel=”next” para sinalizar que essas páginas fazem parte de uma sequência.
Obs: não aplique a canonical se cada página apresentar conteúdo exclusivo, como em um fórum de discussão cujas páginas trazem posts distintos.
Ponto importante: use sempre URLs absolutos!
Para evitar ambiguidades e garantir que os mecanismos de busca interpretem corretamente a versão oficial da sua página, sempre utilize a URL completa, incluindo protocolo e domínio na tag canonical.
Exemplo: <link rel=”canonical” href=”https://exemplo.com.br/blog/” />
Exemplo incorreto: <link rel=”canonical” href=”/blog/” />
Auditoria de canonical para proteger seu site da duplicidade de páginas
Em cerca de 30 minutos, você identifica canonicals inválidas, URLs duplicadas e loops que diluem autoridade. Tudo com ferramentas acessíveis — sem depender de soluções complexas.
1. Varredura completa do site
- Ferramenta: Screaming Frog
- Modo: Spider; inicie o rastreamento no domínio.
- Configuração: em Configuration > Spider, marque Extract canonical.
- Ao concluir o rastreamento: acesse Reports > Canonicals > Non-200 Response e exporte o CSV.
Foque em:
- Canonicals apontando para respostas 3xx, 4xx ou 5xx.
- Páginas sem canonical própria (self-canonical).
- Mais de uma tag canonical no mesmo <head>.
2. Identificação de clusters duplicados
- Ferramenta: OnCrawl
- Acesse Duplicate Content > Clusters.
- Aplique filtro em user-selected canonical.
Você verá:
- Grupos de URLs que o Google pode consolidar por conta própria.
- Onde convém combinar canonical + redirect para evitar dispersão de sinais.
3. Verificação algorítmica
- Ferramenta: Ahrefs Site Audit
- Navegue em Duplicate Content > Issues.
- Confira o item “Duplicate without user-selected canonical”.
Identifique:
- Páginas que o robô já considera equivalentes.
- Aqueles URLs que possuem mais backlinks — ajuste esses casos primeiro.
4. Revisão manual pontual
- Ferramenta: terminal ou navegador
- Execute curl -I https://dominio.com/url
- ou abra o código-fonte e busque rel=”canonical”.
Verifique se:
- A canonical coincide exatamente com a URL exibida.
- Os cabeçalhos Link: <…>; rel=”canonical” não apresentam erros.
5. Elaboração do plano de ação
- Consolide os arquivos CSV em um Google Sheets (use o template da equipe).
- Colunas mínimas: URL | Problema | Prioridade.
- Classifique cada item por impacto (tráfego + autoridade).
6. Execução das correções
- Transforme a planilha em tarefas objetivas e distribua conforme prioridade e responsabilidades.
Em aproximadamente 30 minutos de trabalho, você tem uma lista precisa de ações, recuperando sinais de ranqueamento e economizando o orçamento de rastreamento.
Recomendação: realize essa auditoria a cada grande deploy ou, no mínimo, a cada trimestre. Canonical é um detalhe técnico, mas uma configuração incorreta pode levar o Google a desperdiçar recursos de rastreamento e prejudicar seu posicionamento.
Melhores práticas para canonical
Um bom especialista antecipa oscilações de posicionamento antes que comprometam sua visibilidade. Sendo assim, é importante se atentar a algumas boas práticas de utilização da tag canonical. Confira, abaixo, algumas dicas Hedgehog.
1. Canonical não é redirect (e vice-versa)
Como vimos, canonical não é o mesmo que redirecionamento. Portanto, se certifique de que tudo esteja bem amarrado: o redirect 301 empurra todo o tráfego para uma única URL. Canonical apenas consolida sinais.
- Quando usar redirect: quando a URL antiga perdeu valor ou precisa ser removida — aplique um 301 e pronto.
- Quando usar canonical: se deseja ranquear “/pt/” e “/en/” separadamente, cada uma deve ter canonical própria — evite redirecionamentos. Utilize a estratégia mais adequada para cada situação.
2. Esquema, host e barra final idênticos
http://, https://, www. e aquela “/” no fim parecem detalhes, mas geram versões distintas da mesma página. Divergência = Google confuso.
Regra prática: copie a URL exatamente como aparece na barra do navegador e cole no rel=”canonical”. Simples assim:
https://www.exemplo.com/produto
3. Página-alvo deve responder 200 OK
Se a canonical apontar para uma URL que retorna 301, 404 ou 500, o Google irá ignorá-la.
Antes de subir a página, execute no terminal:
curl -I https://example.com
Se o retorno não for 200 OK, ajuste o servidor ou a configuração para garantir o acesso. Ferramentas de rotina incluem Screaming Frog e soluções de monitoramento contínuo.
4. Nada de UTM ou parâmetros na canonical
Parâmetro mede campanha, não define conteúdo. Deixar “?utm=facebook” na canonical gera variantes infinitas e dilui sinais.
- Canonical limpa: https://exemplo.com/produto/camisa-verde
- As parametrizações devem ser feitas usando parâmetros UTM e, caso seja necessário rastrear cliques, inclua o atributo rel=”nofollow”.
5. Canonical e hreflang
Se o hreflang não estiver alinhado com a canonical, o Google pode confundir versões de idiomas e regiões.
- Defina uma canonical específica para cada idioma.
- Em seguida, utilize o hreflang para conectar todas as versões entre si.
Isso garante um agrupamento organizado, evita sinalizações conflitantes e assegura que cada versão seja indexada corretamente para o público-alvo.
Regra de ouro: se a canonical parece um detalhe pequeno demais para ser importante… revise de novo. Pequenas inconsistências podem prejudicar a eficácia de rastreamento e se tornar canibalização amanhã.
O que fazer quando o Google ignora sua canonical e escolhe outra página?
Você inspeciona no Search Console aquela URL que gera mais conversões e… “Canonical selecionada pelo Google: outra página.”
O algoritmo decide por conta própria que existe uma versão diferente que considera mais adequada do seu conteúdo. Antes de entrar em pânico, siga este procedimento para recuperar o controle da canonical e orientar o Google corretamente.
1. Verifique se há duplicidade de verdade
Abra as duas páginas lado a lado — HTML, título, headings, texto. Se a única diferença for cor de botão ou parâmetros UTM, o Google está certo em tratá-las como duplicatas.
Ferramentas rápidas que podem auxiliar nesse processo: diffchecker.com ou inspeção visual em duas abas.
2. Reforce a autoridade da página correta
- Garanta que a página desejada tenha um self-canonical configurado corretamente.
- Ajuste todos os links internos para apontarem apenas para essa URL. Se necessário, crie um redirecionamento 301 diretamente para a URL escolhida.
- Inclua-a no sitemap.xml. Use o CMS ou um rastreamento com Screaming Frog (Bulk Export > Inlinks) para confirmar que todos os links internos seguem a versão correta.
3. Reduza a visibilidade da versão incorreta
- Aplique noindex na página que não deve ser considerada principal.
- Se a versão indevida aparecer em algum menu ou breadcrumb, atualize a navegação para apontar à página correta.
4. Compare a autoridade e o histórico
Verifique se a outra versão recebe mais backlinks ou tráfego; se for o caso, talvez ela deva ser a canonical oficial. Use ferramentas como Ahrefs ou Google Search Console > Links para confirmar antes de tomar essa decisão.
5. Peça reavaliação ao Google
Quando tudo estiver alinhado, volte ao Search Console, reinspecione a URL que você quer como principal e clique em Solicitar indexação. Isso ajuda a acelerar a atualização do índice.
Aqui, vale reforçarmos: se o Google escolheu outra canonical, não é bug — é sinal fraco. Reforce o que é relevante, elimine as ambiguidades e mostre claramente qual página deve ser priorizada nos resultados de busca.
A canonical serve para orientar o Google sobre qual URL priorizar. A experiência do usuário depende de bons elementos de navegação, estrutura de conteúdo e desempenho do site.
Aqui na Hedgehog, auditamos canonicals diariamente — de grandes e-commerces com milhões de SKUs a blogs corporativos que perdem tráfego por causa de duplicidade.
Quer eliminar páginas fantasmas, loops canônicos e perda de autoridade? Conte com uma agência especializada em SEO como a nossa e veja como aplicamos metodologia e dados para gerar crescimento orgânico consistente. Quem adota as práticas corretas obtém resultados mais sólidos nos mecanismos de busca.